



Ευτυχώς όμως υπάρχει λύση στο πρόβλημά σας, και λέγεται... Everything! (ευφάνταστο όνομα, ε; )
Το Everything είναι μια πανάλαφρη και πανίσχυρη μηχανή αναζήτησης αρχείων και φακέλων για Windows το οποία μπορεί να ψάξει τα περιεχόμενα οποιουδήποτε NTFS δίσκου. Μπορείτε να το κατεβάσετε από εδώ.
Αφού το εγκαταστήσετε και το τρέξετε, θα αντικρύσετε το εξής λιτό παράθυρο.
Ίσως αναρωτηθείτε: «Εεε... που είναι το κουμπί "αναζήτηση"; Και από που επιλέγουμε σε ποιο δίσκο/φάκελο θέλουμε να ψάξουμε;» Η απάντηση είναι απλούστατη: Δεν χρειάζεται ούτε κουμπί "αναζήτηση", ούτε να ορίσετε που θέλετε να ψάξετε. Το Everything εντοπίζει αστραπιαία οτιδήποτε του έχετε γράψει στο πεδίο αναζήτησης ανά πάσα στιγμή, σε οποιοδήποτε σημείο οποιουδήποτε δίσκου κι αν βρίσκεται. Ω ναι.
Θέλετε πχ να ψάξετε που έχετε αποθηκεύσει το Neon Genesis Evangelion. Απλά ξεκινάτε να γράφετε neon ge... και κάπου εκεί η αναζήτηση έχει ήδη λάβει τέλος. Συνολικός χρόνος αναζήτησης: 1 δευτερόλεπτο.

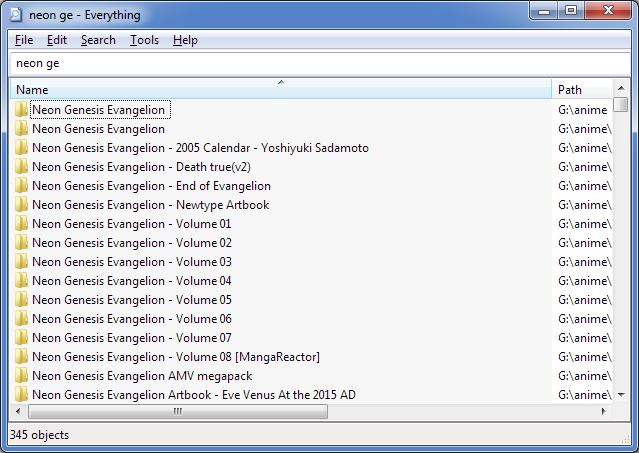
Ναι, είναι όντως τόσο εύκολο, γρήγορο και αποτελεσματικό όσο ακούγεται. Δοκιμάστε το, και δεν θα χρησιμοποιήσετε την αναζήτηση των Windows ποτέ ξανά στη ζωή σας.

Going the extra mile: Regex tutorial
Το Everything είναι ήδη αρκετά δυνατό από μόνο του, με τη standard και προεπιλεγμένη μέθοδο αναζήτησης, αλλά για να διαπιστώσετε τι πραγματικά μπορεί να κάνει και για να αποκτήσετε το μέγιστο έλεγχο και τη μέγιστη ακρίβεια στα αποτελέσματα των αναζητήσεών σας, θα πρέπει να ενεργοποιήσετε τη χρήση regex από το Search menu (εναλλακτικά πατήστε τη συντόμευση [Ctrl]+[R]).
Regex είναι η συντόμευση της φράσης regular expressions. Τα regular expressions είναι συμβολικές παραστάσεις που περιγράφουν μία ή και παραπάνω ακολουθίες χαρακτήρων, οι οποίες ικανοποιούν τις εκάστοτε συνθήκες που επιθυμεί ο χρήστης. Υπάρχουν πολλά regex tutorials στο Internet, αλλά θα προτιμήσω να σας τα εξηγήσω ο ίδιος, γιατί στα tutorials που κυκλοφορούν εκεί έξω εμβαθύνουν πολύ και κινδυνεύετε να χάσετε τη μπάλα. Πάμε λοιπόν βήμα-βήμα να δούμε πως λειτουργούν αυτοί οι διάολοι...

(Σημείωση: Προς το παρόν, η regex στο Everything δεν δουλεύει καλά σε αναζητήσεις με ελληνικούς χαρακτήρες. Ελπίζω αυτό να διορθωθεί σε μελλοντική έκδοση του Everything.)
Καταρχήν, ίσως η σημαντικότερη διαφορά μεταξύ της αναζήτησης που όλοι ξέρετε και της αναζήτησης με χρήση regex είναι ότι στην αναζήτηση με regex το κενό διάστημα δεν χωρίζει keywords, θεωρείται κι αυτό μέρος του keyword. Αν για παράδειγμα ψάξετε για black jack με χρήση regex, το Everything θα σας εμφανίσει μόνο τα αρχεία και τους φακέλους που περιέχουν ακριβώς "black jack" στο όνομά τους. Δεν θα σας εμφανίσει αρχεία και φακέλους που περιέχουν "black_jack", "black-jack", "BlackJack", "Jack Black" κτλ. Αυτό εκ πρώτης όψεως μπορεί να φαίνεται σαν τεράστιο μειονέκτημα, αλλά στην πραγματικότητα τα πάντα γίνονται με σωστή μέθοδο.
Το πρότυπο της regex δεσμεύει ορισμένους χαρακτήρες οι οποίοι έχουν διαφορετικό νόημα από αυτό του εαυτού τους. Χρησιμοποιούνται δηλαδή ως τελεστές που αναφέρονται ή δρουν πάνω σε άλλους χαρακτήρες, και γι' αυτό λέγονται μεταχαρακτήρες. Πάμε να τους δούμε έναν-έναν.
.
Η τελεία είναι ο πιο συχνός μεταχαρακτήρας, και σημαίνει οποιοσδήποτε χαρακτήρας. Τί σημαίνει αυτό στην πράξη; Σημαίνει ότι αν ψάξετε για black.jack, το Everything θα σας εμφανίσει όλα τα αρχεία και τους φακέλους που στο όνομά τους περιέχουν "black jack", black_jack", "black-jack", "black.jack", "black+jack" κτλ κτλ. Δεν θα σας εμφανίσει όμως αρχεία και φακέλους που περιέχουν "jack black" κτλ, ούτε αρχεία/φακέλους που έχουν παραπάνω από δύο χαρακτήρες (ή λιγότερο από έναν) ανάμεσα στο black και στο jack, πχ "black__jack" ή "BlackJack".
?
Το λατινικό ερωτηματικό αναφέρεται στον ακριβώς προηγούμενο απ' αυτό χαρακτήρα, και δηλώνει ότι ο εν λόγω χαρακτήρας υπάρχει ή μία ή καμία φορά στη συγκεκριμένη θέση. Για παράδειγμα, αν θέλετε να ψάξετε για όλες τις JPEG εικόνες που έχετε στον υπολογιστή σας, αρκεί να ψάξετε για αρχεία με κατάληξη jpg ή jpeg. Αυτό με regex γίνεται πανεύκολα, γράφοντας jpe?g. Το λατινικό ερωτηματικό μπορεί επίσης να χρησιμοποιηθεί και μετά από τελεία. Για να συνεχίσουμε το παράδειγμα με τον Black Jack, αν γράψετε black.?jack, το Everything θα σας εμφανίσει όλα τα αρχεία και τους φακέλους που στο όνομά τους περιέχουν "black jack", black_jack", "black-jack" κτλ κτλ ΣΥΝ τα αρχεία και τους φακέλους που περιέχουν "BlackJack" (όχι όμως αποτελέσματα όπως "black__jack").
+
Όπως το ?, έτσι και το + αναφέρεται στον ακριβώς προηγούμενο απ' αυτό χαρακτήρα, και δηλώνει ότι ο εν λόγω χαρακτήρας υπάρχει τουλάχιστον μία φορά στη συγκεκριμένη θέση, κι ενδέχομένως να επαναλαμβάνεται. Αν πχ ψάχνετε μια εικόνα που την έχετε ονομάσει BRAAAAAAAAAAAAAAAINS.jpg, και δεν θυμάστε φυσικά πόσα "A" έχει αυτό το filename στη σειρά, μπορείτε απλούστατα να γράψετε bra+ins. Το + μπορεί επίσης να χρησιμοποιηθεί και μετά από τελεία. Έτσι, στο καθιερωμένο πλέον παράδειγμα με τον Black Jack, αν γράψετε black.+jack, το Everything θα σας εμφανίσει όλα τα αρχεία και τους φακέλους που στο όνομά τους περιέχουν "black jack", black_jack", "black-jack" κτλ κτλ ΣΥΝ τα αρχεία και τους φακέλους που περιέχουν "black__jack", "black_-_jack", "black lagoon - ripped by jack" κτλ (όχι όμως "BlackJack").
Παρεμπιπτόντως παρατηρήστε ότι το .+ δεν σημαίνει ότι ανάμεσα στο "black" και στο "jack" επαναλαμβάνεται ο ίδιος χαρακτήρας. Ουσιαστικά, .+ σημαίνει οποιαδήποτε ακολουθία χαρακτήρων μήκους 1 και πάνω.
*
Όπως το ? και το +, έτσι και ο αστερίσκος αναφέρεται στον ακριβώς προηγούμενο απ' αυτόν χαρακτήρα, και δηλώνει ότι ο εν λόγω χαρακτήρας υπάρχει οσεσδήποτε φορές στη συγκεκριμένη θέση, συμπεριλαμβανομένων και των μηδέν φορών. Δίνει, με άλλα λόγια, το συνδυασμό των αποτελεσμάτων που θα είχαμε με χρήση ? και +. Επίσης όπως το ? και το +, έτσι και ο αστερίσκος, μπορεί να χρησιμοποιηθεί μετά από τελεία, και σημαίνει οποιαδήποτε ακολουθία χαρακτήρων μήκους 0 και πάνω. Αποτελεί δηλαδή τον αντικαταστάτη του διαστήματος στο default search, αρκεί να έχετε γράψει τα keywords με τη σωστή σειρά. Έτσι, για ένα τελευταίο παράδειγμα με τον Black Jack, αν γράψετε black.*jack, το Everything θα σας εμφανίσει οτιδήποτε έχει τη λέξη Black πριν από τη λέξη Jack, από "BlackJack" μέχρι "black -όλο το Πόλεμος Και Ειρήνη του Leo Tolstoy σε μία γραμμή- jack" (όχι όμως αρχεία και φακέλους που περιέχουν "jack black").
|
Η κατακόρυφος είναι τελεστής διάζευξης, δηλαδή ψάχνει για filenames που περιέχουν είτε τη μία είτε την άλλη ακολουθία χαρακτήρων. Αν πχ ψάχνετε για όλες τις εικόνες που είναι ή jpeg ή png, μπορείτε να γράψετε jpe?g|png. Αν θέλετε στα αποτελέσματα να συμπεριλάβετε και αρχεία gif, απλά προσθέτετε κι άλλη κατακόρυφο, δηλαδή jpe?g|png|gif.
$
Το δολάριο μπαίνει στο τέλος μιας ακολουθίας χαρακτήρων, και δηλώνει ότι τα αρχεία και οι φάκελοι που ψάχνουμε έχουν όνομα που τελειώνει μ' αυτήν ακριβώς την ακολουθία. Αν για παράδειγμα θέλετε να βρείτε όλα τα αρχεία doc στον υπολογιστή σας, χωρίς να παρεμβάλλονται μέσα στα αποτελέσματα φάκελοι όπως My Documents και αρχεία όπως doctor.who.2005.s04.e01.avi, μπορείτε απλά να γράψετε doc$.
^
Αντίθετα με το $, το ^ μπαίνει στην αρχή μιας ακολουθίας χαρακτήρων, και δηλώνει ότι τα αρχεία και οι φάκελοι που ψάχνουμε έχουν όνομα που ξεκινά μ' αυτήν ακριβώς την ακολουθία. Για παράδειγμα, αν θέλετε να βρείτε έναν φάκελο που λέγεται "doc" σκέτο. Λίγο δύσκολο να τον βρείτε γράφοντας απλά doc... γράφοντας όμως ^doc, αφαιρούνται αυτομάτως από τα αποτελέσματα όλα τα αρχεία και οι φάκελοι που δεν ξεκινάνε με "doc". Γι' ακόμα καλύτερα αποτελέσματα, γράψτε ^doc$.
(Υπάρχει μία ακόμα ειδική χρήση του ^, τελείως διαφορετική από την κυρίως χρήση που μόλις εξήγησα, η οποία όμως θα χρειαστεί να την εξηγήσω παρακάτω.)
()
Οι παρενθέσεις χρησιμοποιούνται για να ομαδοποιούν χαρακτήρες σε λέξεις, ούτως ώστε να μπορούμε να εφαρμόσουμε μεταχαρακτήρες πάνω σε ολόκληρες λέξεις. Αυτό ίσως ακούγεται ακαταλαβίστικο, οπότε θα το εξηγήσω με ένα παράδειγμα. Έστω ότι ψάχνετε για ένα αρχείο, για το οποίο τα μόνα πράγματα που θυμάστε είναι ότι περιέχει τη λέξη photos στο όνομα, και η κατάληξη είναι ή rar ή zip. Με τις όσες γνώσεις έχετε μέχρι τώρα, ίσως γράφατε photos.*rar|zip$. Αυτό όμως είναι λάθος διότι θα σας βγάλει στα αποτελέσματα α) όσα αρχεία έχουν μέσα στο όνομά τους τη λέξη "photos" πριν τη λέξη "rar" (με το rar να μην είναι απαραίτητα κατάληξη αρχείου), καθώς και β) ΟΛΑ τα αρχεία που έχουν κατάληξη zip. Για να βρείτε αυτό που θέλετε πρέπει να γράψετε photos.*(rar|zip)$. Μ' αυτόν τον τρόπο, το $ αναφέρεται στο περιεχόμενο των παρενθέσεων, και όχι απλά στο zip όπως πριν.
[]
Και τώρα οι αγκύλες, για τις οποίες πρέπει να εξηγήσω τα περισσότερα... XD
Οι αγκύλες κάνουν κάτι παρόμοιο με την κατακόρυφο, αλλά για μεμονωμένους χαρακτήρες. Πιο συγκεκριμένα, ορίζουν ότι στη συγκεκριμένη θέση μπορεί να υπάρχει μόνο ένας χαρακήρας από το σύνολο των χαρακτήρων που βρίσκονται μέσα στις αγκύλες. Για παράδειγμα, αν ψάχνετε για D.Gray-man στον υπολογιστή σας, αλλά υποψιάζεστε ότι μερικά αρχεία ίσως έχουν το λάθος spelling "D.Grey-man", μπορείτε να ψάξετε και για τα δύο ταυτόχρονα γράφοντας d.gr[ae]y.man. Έχει δηλαδή το ίδιο αποτέλεσμα με το d.gr(a|e)y.man, αλλά φυσικά είναι πιο εύκολο να γράψετε [ae] παρά (a|e).
Υπάρχουν δύο τρόποι (well, τρεις, αλλά ο τρίτος είναι πολύ ειδική περίπτωση και θα τον αναφέρω ξεχωριστά παρακάτω) για να ορίσετε σύνολα χαρακτήρων με αγκύλες. Ο ένας, όπως ήδη είδαμε παραπάνω, είναι να τους γράψουμε όλους έναν-έναν. Πχ για ένα οποιοδήποτε φωνήεν του λατινικού αλφάβητου, γράφετε [aeiou]. Ο δεύτερος τρόπος προσφέρεται όταν οι χαρακτήρες που θέλουμε να συμπεριλάβουμε στο σύνολο είναι διαδοχικοί, στην οποία περίπτωση μπορούμε να τους περιγράψουμε σαν εύρος, αντί να καθόμαστε να τους γράφουμε όλους έναν-έναν. Για παράδειγμα, ένα οποιοδήποτε δεκαδικό ψηφίο εκφράζεται σε regex ως [0-9] (κι έχει το ίδιο αποτέλεσμα με το [0123456789]), ένα οποιοδήποτε γράμμα μεταξύ a και f περιγράφεται ως [a-f] (κι έχει το ίδιο αποτέλεσμα με το [abcdef]), κι ένα οποιοδήποτε δεκαεξαδικό ψηφίο περιγράφεται ώς [0-9a-f] (κι έχει το ίδιο αποτέλεσμα με το [0123456789abcdef]).
Παρατηρήστε δύο πράγματα στα παραπάνω παραδείγματα. Αφενός, μπορούμε να συνδυάσουμε δύο διαφορετικά εύρη (εν προκειμένω 0-9 και a-f) απλούστατα γράφωντάς τα το ένα δίπλα στο άλλο, δίχως κανένα διαχωριστικό ανάμεσά τους. Αφετέρου, και πολύ σημαντικό, στα συγκεκριμένα παραδείγματα η παύλα λειτουργεί σαν μεταχαρακτήρας. Αν δεν λειτουργούσε, τότε το [0-9] δεν θα έψαχνε για κάθε ψηφίο από 0 έως 9, αλλά για α) το 0, β) την παύλα και γ) το 9. Δηλαδή δεν θα ήταν ισοδύναμο με το [0123456789], αλλά με το (0|-|9). Γι' αυτό λοιπόν, προσοχή όταν γράφετε την παύλα μέσα σε αγκύλες. Αν δεν θέλετε να ψάξετε για κανένα εύρος αλλά απλά για μεμονωμένους χαρακτήρες, και η παύλα είναι ένας απ' αυτούς, βάλτε την είτε πρώτη είτε τελευταία μέσα στις αγκύλες. Όχι ανάμεσα, διότι τότε κατευθείαν θα δουλέψει σαν μεταχαρακτήρας και το Everything θα νομίζει ότι ψάχνετε και για οποιοδήποτε χαρακτήρα που βρίσκεται αλφαβητικά μεταξύ του χαρακτήρα που είναι αμέσως πριν την παύλα και του χαρακτήρα που είναι αμέσως μετά. Αν λοιπόν σε κάποιο σημείο θέλετε πχ να ψάξετε είτε για το γράμμα a, είτε για το γράμμα f, είτε για την παύλα, τότε αντί για [a-f] γράφετε [af-].
Τέλος, ο τρίτος και ξεχωριστός τρόπος να ορίσετε σύνολα είναι μέσω άρνησης, δηλαδή ορίζοντας ποιοι χαρακτήρες ΔΕΝ ανήκουν στο σύνολο. Αυτό γίνεται με αγκύλες το περιεχόμενω των οποίων ξεκινά με ^, για παράδειγμα [^abc]. Αυτή είναι η ειδική χρήση του ^ για την οποία δεν μπορούσα να μιλήσω στη δική του παράγραφο, διότι έπρεπε να εξηγήσω τις αγκύλες πρώτα. Έτσι λοιπόν, για να δώσω μερικά παραδείγματα, αν ψάχνετε για αρχεία και φακέλους που έχουν μέσα στο όνομά τους τη λέξη "john", χωρίς όμως αυτό το "john" να είναι απλά μέρος του "johnny", αρκεί να γράψετε john[^n]. Επιπλέον, για να βρείτε πχ οτιδήποτε έχει "temp" μέσα στο όνομά του εξαιρώντας αυτά που ξεκινάνε με "temp", γράφετε [^^]temp. Το [^^] είναι η άρνηση του απλού ^, και σημαίνει ότι οτιδήποτε ακολουθεί δεν μπορεί να είναι η αρχή του ονόματος. Τέλος, για να βρείτε πχ οτιδήποτε έχει "exe" μέσα στο όνομά του εξαιρώντας αυτά που τελειώνουν σε exe, γράφετε exe[^$]. Το [^$] είναι η άρνηση του απλού $, και σημαίνει ότι οτιδήποτε προηγείται δεν μπορεί να είναι το τέλος του ονόματος.
{}
Τα άγκιστρα αναφέρονται στον ακριβώς προηγούμενο απ' αυτά χαρακτήρα, και δηλώνουν ότι ο συγκεκριμένος χαρακτήρας υπάρχει ακριβώς χ φορές στη συγκεκριμένη θέση, όπου χ ο αριθμός που έχουμε βάλει μέσα στα άγκιστρα. Ίσως αναρωτιέστε πόσο χρήσιμο μπορεί να αποδειχτεί κάτι τέτοιο στην πράξη, αλλά σας έχω έτοιμα δύο αρκετά ενδιαφέροντα παραδείγματα. Πρώτον, έστω ότι θέλετε να βρείτε όλες τις εικόνες που έχετε αποθηκεύσει από το 4chan χωρίς να τους αλλάξετε filename. Οι εικόνες που αποθηκεύετε από το 4chan έχουν filename (ένας 13-ψήφιος αριθμός).jpg (ή png ή gif). Αυτό με regex περιγράφεται πανεύκολα γράφοντας ^[0-9]{13}.(jpe?g|png|gif)$. Ένα ακόμα παράδειγμα είναι οι εικόνες που έχετε αποθηκεύσει από το Danbooru χωρίς να τους αλλάξετε filename. Οι εικόνες από το Danbooru έχουν filename (ένας 32-ψήφιος δεκαεξαδικός αριθμός).jpg (ή png ή gif). Αυτό με regex περιγράφεται γράφοντας ^[0-9a-f]{32}.(jpe?g|png|gif)$. Επίσης, εντός αγκίστρων μπορείτε να ορίσετε κι ένα εύρος τιμών. Πχ αν θέλετε να βρείτε όλα τα αρχεία και τους φακέλους με ονόματα που κυμαίνονται μεταξύ 40 και 50 χαρακτήρων, μπορείτε να γράψετε ^.{40,50}$. Παρατηρήστε παρεμπιπτόντως ότι το κόμμα λειτουργεί σαν μεταχαρακτήρας μόνο σ' αυτήν την περίπτωση, πουθενά αλλού.
\
Επίτηδες άφησα για το τέλος την ανάποδη κάθετο, η οποία είναι ο μεταχαρακτήρας διαφυγής. Αναφέρεται στον ακριβώς επόμενο (όχι προηγούμενο τούτη τη φορά) απ' αυτήν χαρακτήρα, και δηλώνει ότι ο εν λόγω χαρακτήρας δεν λειτουργεί ως μεταχαρακτήρας, αλλά είναι ακριβώς ο χαρακτήρας που ψάχνουμε στο συγκεκριμένο σημείο. Θα δώσω πολλά παραδείγματα γι' αυτό. Έστω ότι θέλετε να βρείτε όλα τα αρχεία με κατάληξη nfo που έχετε στον υπολογιστή σας. Ακόμα κι αν γράψετε nfo$, μέσα στα αποτελέσματα θα παρεμβάλλονται και πολλοί φάκελοι που το όνομά τους τελειώνει σε "info". Γράφοντας όμως \.nfo$ εξαλείφετε αυτά τα παραπανίσια αποτελέσματα (το να γράφατε σκέτο .nfo$ δεν θα βοηθούσε σε τίποτα, για λόγους που by now θα πρέπει να σας είναι κατανοητοί). Αν θέλετε να βρείτε όλα τα fansubs των [gg] που έχετε στον υπολογιστή σας, μπορείτε να γράψετε \[gg\]. Αν θέλετε να βρείτε όλα τα αρχεία mp3 που περιέχουν "(live)" στο όνομά τους, μπορείτε να γράψετε \(live\).*mp3$. Για να συμπεριλάβετε και τα αρχεία mp3 που περιέχουν "[live]" στο όνομά τους, γράφετε (\(|\[)live(\)|\]).*mp3$.
~
Αυτά τα... ολίγα.
 Πραγματικά ελπίζω να μην έχω παραλείψει τίποτα (μου πήρε και μέρες να το γράψω το ρημάδι). Είμαι σίγουρος ότι θα σας φαίνονται βουνό όλα στην αρχή, αλλά μην αποθαρρύνεστε. Δεν χρειάζεται κανείς να είναι διάνοια για να μάθει regex, και σχεδόν κανείς δεν την έμαθε σε μία μέρα. Προσπάθησα όσο καλύτερα μπορούσα να γίνονται όλα όσα γράφω κατανοητά με την πρώτη ανάγνωση, αλλά αν έχετε την οποιαδήποτε παραμικρή απορία, μη διστάσετε να τη γράψετε σ' αυτό το thread, και θα σας εξηγήσω οτιδήποτε σας μπερδεύει.
Πραγματικά ελπίζω να μην έχω παραλείψει τίποτα (μου πήρε και μέρες να το γράψω το ρημάδι). Είμαι σίγουρος ότι θα σας φαίνονται βουνό όλα στην αρχή, αλλά μην αποθαρρύνεστε. Δεν χρειάζεται κανείς να είναι διάνοια για να μάθει regex, και σχεδόν κανείς δεν την έμαθε σε μία μέρα. Προσπάθησα όσο καλύτερα μπορούσα να γίνονται όλα όσα γράφω κατανοητά με την πρώτη ανάγνωση, αλλά αν έχετε την οποιαδήποτε παραμικρή απορία, μη διστάσετε να τη γράψετε σ' αυτό το thread, και θα σας εξηγήσω οτιδήποτε σας μπερδεύει.






















